

In our previous blog "Amazon SageMaker Pricing and Optimization", we explored Amazon SageMaker pricing and how it can be a game-changer for machine learning projects. However, as powerful as SageMaker is, its costs can escalate quickly if not managed effectively.
In this blog, we will explore 7 effective strategies to reduce your SageMaker expenses while maintaining high performance.
1. Use SageMaker Multi-Model Endpoints (MME)

SageMaker Multi-Model Endpoints (MME) can reduce costs by hosting multiple models on a single endpoint, eliminating the need for separate instances for each model. It enables dynamic model loading, ensuring only active models use GPU resources. MME also allows you to use smaller GPU instances and supports model optimizations like TensorRT, reducing the computational resources required. With auto-scaling, resources adjust based on demand, and consolidated billing lowers infrastructure costs. Overall, MME optimizes resource usage and reduces operational expenses.
The image above shows how Amazon SageMaker Multi-Model Endpoints (MME) load models dynamically from Amazon S3, reducing costs by sharing a single endpoint. Instead of keeping all models in memory, MME loads only the requested model (e.g., rideshare.tar.gz), optimizing resources and improving scalability.
Example scenario to demonstrate potential savings:
TechVerse AI, a company specializing in developing machine learning models for various clients, frequently deploys multiple models for real-time inference. They used to deploy each model on a separate endpoint, which resulted in high costs for maintaining numerous endpoints, especially when many models were inactive.
To optimize costs, TechVerse AI decides to use SageMaker Multi-Model Endpoints (MME), which allows them to host multiple models on a single endpoint and load only the models that are in active use. This dynamic model loading reduces the need for multiple instances and helps optimize GPU resources, ensuring that only active models utilize the GPU resources.
Current Costs
- Instance Type: ml.g4dn.xlarge (GPU Instance)
- Cost per instance per hour: $0.75
- Number of models deployed: 5
- Separate endpoints for each model, running 24/7
- Monthly usage for each model: 730 hours (24/7)
- Monthly Cost Calculation:
5 models × 730 hours/model × $0.75/hour = $2,737.50/month
Optimized Costs – Implementing Multi-Model Endpoints (MME)
- MME allows hosting 5 models on a single endpoint with dynamic model loading
- Instance Type: ml.g4dn.xlarge (GPU Instance)
- Total monthly usage for all models: 730 hours (since only one instance is required for all models)
- Monthly Cost Calculation:
1 instance × 730 hours × $0.75/hour = $547.50/month
Savings
- Monthly Savings: $2,737.50 − $547.50 = $2,190
- Annual Savings: $2,190 × 12 = $26,280
By consolidating multiple models onto a single endpoint using SageMaker Multi-Model Endpoints, TechVerse AI saves $26,280 annually, which is an 80% reduction in costs compared to the previous setup with multiple endpoints.
2. Implement SageMaker Lifecycle configurations
Implementing SageMaker Lifecycle configurations helps reduce costs by automatically managing the start and stop times of Studio notebooks. By defining specific start and stop schedules, you ensure that notebooks only run when actively needed. For example, you can configure notebooks to automatically shut down after business hours and restart during the next workday. This prevents idle instances from running overnight or during non-peak hours, directly reducing compute costs.
By setting these configurations, you can ensure that compute resources are used efficiently, only consuming charges when the notebooks are in active use, helping you avoid unnecessary expenses.
Here's the proper AWS CLI command to create a SageMaker Lifecycle Configuration that includes an automatic shutdown of the notebook instance:
Create the stop script (stop-notebook.sh)\
Create the Lifecycle Configuration
Attach the Lifecycle Configuration to a Notebook Instance
Example scenario to demonstrate potential savings:
DataInsight Analytics, a data science firm, currently utilizes SageMaker On-Demand Notebook Instances for running machine learning models and exploratory data analysis.Their team frequently uses ml.t3.medium instances for developing models, often leaving them running overnight and on weekends, leading to unnecessary costs.
To optimize costs, DataInsight Analytics plans to implement SageMaker Lifecycle Configurations, which will automatically shut down notebooks after business hours and restart them only during active usage periods.
Current Costs
- Notebook Instance Type: ml.t3.medium
- Cost per instance per hour: $0.058
- Usage without Lifecycle Configuration: 24/7 (730 hours/month)
- Monthly Cost Calculation: 1 instance × 730 hours × 0.058 = $42.34
Optimized Costs – Implementing Lifecycle Configuration
- Usage with Lifecycle Configuration: 8 hours/day, 22 days/month (176 hours/month)
- Monthly Cost Calculation: 1 instance × 176 hours × 0.058 = $10.21
Savings
- Monthly Savings: $42.34 − $10.21 = $32.13
- Annual Savings: 32.13 × 12 = $385.56
If DataInsight Analytics has 10 such notebooks, the total annual savings would be $3,855.60.
By scheduling Data Wrangler jobs using Amazon EventBridge, InsightAnalytics can save $41,400 annually, reducing their compute costs by 95.83%. This ensures that resources are used efficiently, with jobs running only when necessary.
3. Implement Amazon SageMaker Savings Plans
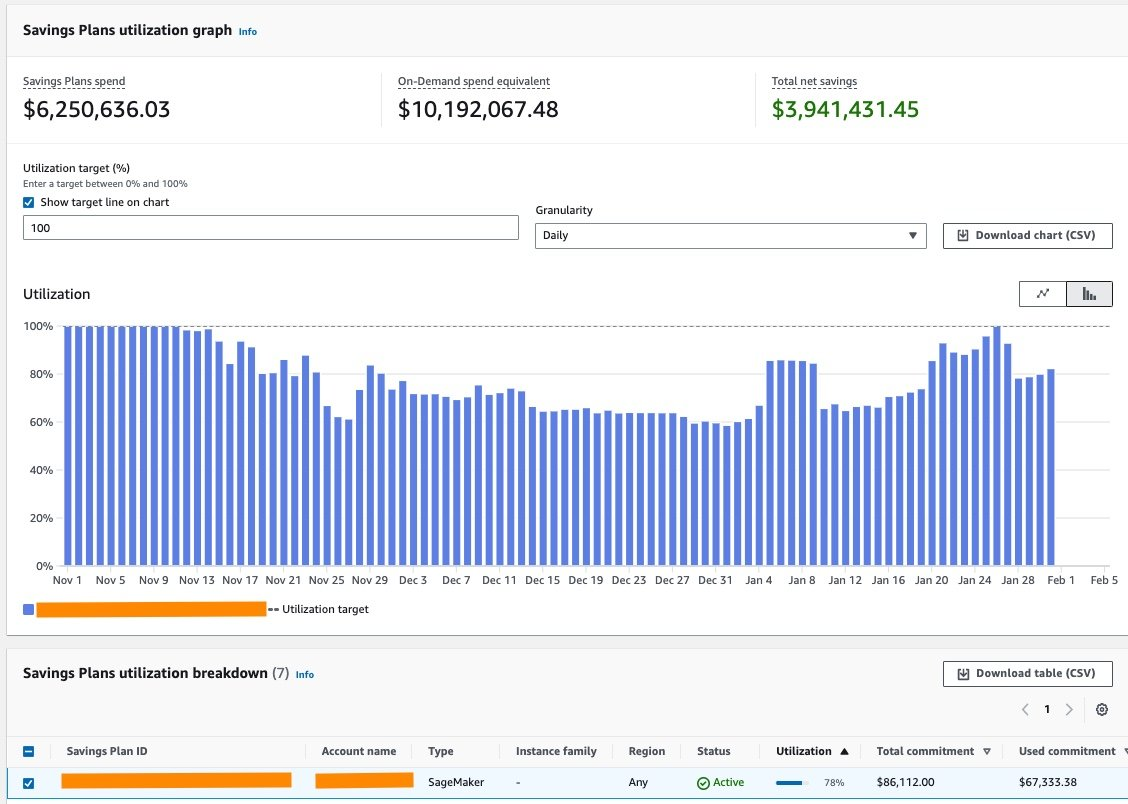
Amazon SageMaker Savings Plans offer up to 64% savings by committing to consistent usage over a 1- or 3-year term. This model applies to services like Studio notebooks, training, and inference, regardless of instance type or region. You pay the Savings Plan rate for usage within your commitment, with any excess usage billed at On-Demand rates. Use AWS Cost Management Console to get recommendations based on your historical usage, helping you choose the right commitment and payment option (No Upfront, Partial, or All Upfront). Monitoring utilization reports ensures you're maximizing savings and not over-committing.
The utilization report shows that even with less than 100% coverage on some days, you still save compared to On-Demand rates. To maximize savings, choose the right commitment based on consistent usage and monitor your plan to avoid over-committing.
Here's a table comparing the 1-year and 3-year Amazon SageMaker Savings Plans:
4. Schedule Data Wrangler job instances
Amazon SageMaker Data Wrangler is a powerful tool that simplifies the process of data preparation and feature engineering for machine learning (ML) workflows. It provides an intuitive interface to import, clean, transform, and visualize data from multiple sources such as Amazon S3, Redshift, Athena, and Snowflake, reducing the time spent on data preprocessing. Data Wrangler supports built-in transformations, custom Pandas or PySpark scripts, feature selection, and data quality analysis, allowing ML practitioners to streamline their data workflows without managing separate tools. Additionally, it integrates seamlessly with SageMaker Pipelines, Feature Store, and SageMaker Training, making it a crucial component in ML model development.
Using Amazon EventBridge to schedule SageMaker Data Wrangler jobs helps reduce costs by optimizing compute usage and preventing unnecessary executions. Instead of running Data Wrangler jobs manually or continuously, EventBridge can trigger a SageMaker Processing Job at scheduled intervals, such as daily or hourly, ensuring that compute resources are only used when needed. This approach prevents idle compute usage and reduces On-Demand instance costs by running jobs only at predefined times.
Example Code for Scheduling Data Wrangler Job with EventBridge:
This code sets up a scheduled rule to run your Data Wrangler job daily, ensuring the process is automated.
Example scenario to demonstrate potential savings:
"Insight Tech" , a data-driven company, uses Amazon SageMaker Data Wrangler for data preparation and feature engineering in their machine learning workflows. However, running Data Wrangler jobs continuously or manually consumes unnecessary compute resources, leading to higher costs.
By scheduling Data Wrangler jobs using Amazon EventBridge, Insight Tech can optimize compute usage by triggering jobs at predefined intervals, such as daily or hourly. This reduces idle compute time and cuts down on On-Demand instance costs.
Current Costs
- Total compute time: 24 hours/day * 30 days = 720 hours per month.
- Monthly cost = 720 hours * $5/hour = $3,600.
Optimized Costs - Scheduling with EventBridge
- Schedule Data Wrangler jobs to run daily via EventBridge.
- Compute usage: 1 hour per job (once per day).
- Total compute time = 1 hour/day * 30 days = 30 hours per month.
- Monthly cost = 30 hours * $5/hour = $150.
Savings Calculation
- Monthly Savings = $3,600 (current cost) - $150 (optimized cost) = $3,450.
- Annual Savings = $3,450 * 12 months = $41,400.
By scheduling Data Wrangler jobs using Amazon EventBridge, Insight Tech can save $41,400 annually, reducing their compute costs by 95.83%. This ensures that resources are used efficiently, with jobs running only when necessary.
5. Automate Data Cleanup
When using Athena or Redshift as data sources, SageMaker automatically copies the data to Amazon S3. However, after the job completes, the data remains in S3, potentially incurring unnecessary storage costs. To avoid this, implement an automatic cleanup process (e.g., using a Lambda function) to remove the data from S3 once the processing job is complete, reducing unwanted storage charges.
Here's an example Lambda function:
Example scenario to demonstrate potential savings:
DataScience Co., a firm specializing in data analysis and machine learning, uses Amazon Athena and Redshift as data sources for their SageMaker processing jobs. After each job, the processed data is stored in Amazon S3. However, the data remains in S3 long after it is no longer needed, leading to unnecessary storage costs. To address this, DataScience Co. decides to automate the cleanup process using an AWS Lambda function to delete the data from S3 once the processing job is complete.
Current Costs
- Data source: Athena and Redshift
- Monthly data storage in S3 (unused data): 1 TB
- S3 storage cost per GB per month: $0.023
- Monthly Storage Cost Calculation:
1,000 GB × $0.023 = $23/month for unused data storage
Optimized Costs – Automating Data Cleanup
- Implement AWS Lambda function to automatically delete data from S3 after the processing job is completed
- Monthly data storage in S3 (after cleanup): 0 GB (data is deleted automatically after use)
- Monthly Storage Cost Calculation:
0 GB × $0.023 = $0/month (no unused data storage)
Savings
- Monthly Savings: $23 − $0 = $23
- Annual Savings: $23 × 12 = $276
By automating data cleanup using an AWS Lambda function to remove processed data from S3, DataScience Co. eliminates $276 in unnecessary storage costs annually. This results in a 100% reduction in storage costs for unused data, ensuring that only the necessary data is kept, significantly optimizing storage expenses.
6. Avoid Costs in Processing and Pipeline Development

To avoid unnecessary costs during SageMaker processing and pipeline development, it's crucial to examine historic job metrics. You can use the Processing page on the SageMaker console or the list_processing_jobs API to analyze job performance, identify inefficiencies, and avoid frequent failures. During the development phase, leverage SageMaker Local Mode to test your scripts and pipelines locally before deploying them in the cloud. This mode allows you to run estimators and processors on your local machine, reducing cloud resource consumption and costs.
By validating and debugging your jobs locally, you can optimize them before scaling on SageMaker, ensuring cost-efficient processing.
Example scenario to demonstrate potential savings:
"DataTech Solutions," a data science company, uses Amazon SageMaker for processing large datasets and developing machine learning pipelines. To reduce cloud resource consumption and costs, they can optimize the development process by using SageMaker Local Mode for testing and debugging before deploying jobs to the cloud.
Current Costs
- Job Duration: 10 hours per job in the cloud.
- Total Jobs: 7 jobs (4 successful, 3 failures).
- Cloud Instance Cost: $5/hour.
- Monthly Cost Calculation:Total time on cloud = 7 jobs * 10 hours = 70 hours.
- Monthly cost = 70 hours * $5/hour = $350.
Optimized Costs - Using SageMaker Local Mode
- Local Testing: 10 hours for local testing.
- Cloud Usage: 4 successful jobs, each taking 10 hours.
- Cost Calculation after Optimization:
- Total time on cloud = 4 jobs * 10 hours = 40 hours.
- Monthly cost = 40 hours * $5/hour = $200.
Savings Calculation:
- Monthly Savings = $350 (current cost) - $200 (optimized cost) = $150.
- Annual Savings = $150 * 12 months = $1,800.
By using SageMaker Local Mode, DataTech Solutions can save $1,800 annually, reducing their cloud processing costs by 42.86%.
7. Optimize Batch Transform Jobs
Batch Transform in Amazon SageMaker is a process for generating predictions on large datasets in bulk, typically when real-time inference (real-time endpoints) is not necessary or feasible.
To optimize costs for SageMaker batch transform jobs, focus on efficient compute resource usage. Adjust the batch size to fit memory limits and reduce job duration. Use the MultiRecord strategy for larger datasets and combine small files to minimize S3 interactions. Optimize MaxPayloadInMB and MaxConcurrentTransforms to align with the instance's vCPU count, improving parallelization and reducing job time.
For large datasets, scale horizontally by using multiple instances. Monitor job performance through CloudWatch to identify bottlenecks and adjust resources as needed. Finally, set S3 lifecycle rules to clean up incomplete uploads and avoid unnecessary storage costs.
Example scenario to demonstrate potential savings:
RetailData Insights uses Amazon SageMaker Batch Transform for generating predictions on large datasets. Initially, they ran jobs without optimizing resources, leading to high compute and storage costs due to suboptimal batch sizes and inefficiencies.
To optimize, they adjusted batch sizes, used the MultiRecord strategy, combined small files, optimized settings for parallelization, and horizontally scaled with 3 instances. They also implemented S3 lifecycle rules to clean up incomplete uploads.
Current Costs
- Instance Type: ml.m5.4xlarge
- Cost per instance: $1.20/hour
- Job duration: 5 hours/job
- Monthly Cost: $180
Optimized Costs
- Instance Type: ml.m5.4xlarge
- Job duration reduced to 3 hours/job with 3 instances
- Optimized Monthly Cost: $324
Savings
- Monthly Savings: $54
- Annual Savings: $648
- Percentage Savings: 30%
By optimizing job settings and scaling, RetailData Insights saves 30% in compute costs, resulting in $648 annual savings.
References
Conclusion
By implementing strategies like Multi-Model Endpoints, Lifecycle configurations, and Savings Plans, businesses can significantly reduce Amazon SageMaker costs. Optimizing job scheduling and automating tasks such as data cleanup further enhances cost efficiency. These approaches help maintain performance while managing expenses effectively.



.jpeg)
